kernel pwn(二)权限提升
kernel_pwn的权限提升很重要。从一个普通用户变成root用户,可以上升到get flag的权限。学习一下吧。
题目链接:https://github.com/z1r00/ctf-pwn/tree/main/kernel_pwn/ciscn_babydriver
权限基础
内核提权指的是普通用户可以获取到 root 用户的权限,访问原先受限的资源。这里从两种角度来考虑如何提权
- kernel_pwn改变自身:通过改变自身进程的权限,使其具有 root 权限。
- 改变别人:通过影响高权限进程的执行,使其完成我们想要的功能。
内核会通过进程的 task_struct 结构体中的 cred 指针来索引 cred 结构体,然后根据 cred 的内容来判断一个进程拥有的权限,如果 cred 结构体成员中的 uid-fsgid 都为 0,那一般就会认为进程具有 root 权限。cread结构体在include/linux/cred.h这里
1 | struct cred { |
既然uid-fsgid为0就可以拿到root权限,我们可以这样提权
- 修改结构体的对应的id为0
- 修改 task_struct 结构体中的 cred 指针指向一个满足要求的 cred
我们要做的就是定位cred结构体,修改id/修改cred指针
改变自身
直接改cread的id
定位结构体
首先我们肯定得找到结构的位置。有两种方法(直接定位和间接定位)
直接定位
cred 结构体的最前面记录了各种 id 信息,对于一个普通的进程而言,uid-fsgid 都是执行进程的用户的身份。因此我们可以通过扫描内存来定位 cred。
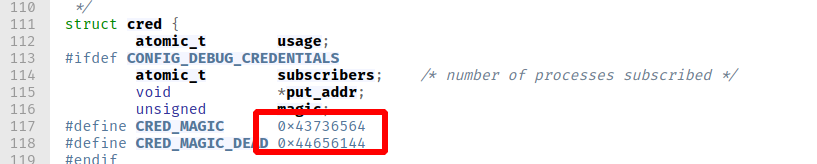
在实际定位的过程中,我们可能会发现很多满足要求的 cred,这主要是因为 cred 结构体可能会被拷贝、释放。一个很直观的想法是在定位的过程中,利用 usage 不为 0 来筛除掉一些 cred,但仍然会发现一些 usage 为 0 的 cred。这是因为 cred 从 usage 为 0, 到释放有一定的时间。此外,cred 是使用 rcu 延迟释放的。
间接定位
task_struct
进程的 task_struct 结构体中会存放指向 cred 的指针,因此我们可以
- 定位当前进程
task_struct结构体的地址 - 根据 cred 指针相对于 task_struct 结构体的偏移计算得出
cred指针存储的地址 - 获取
cred具体的地址
1 | /* Tracer's credentials at attach: */ |
comm
comm 用来标记可执行文件的名字,位于进程的 task_struct 结构体中。我们可以发现 comm 其实在 cred 的正下方,所以我们也可以先定位 comm ,然后定位 cred 的地址。
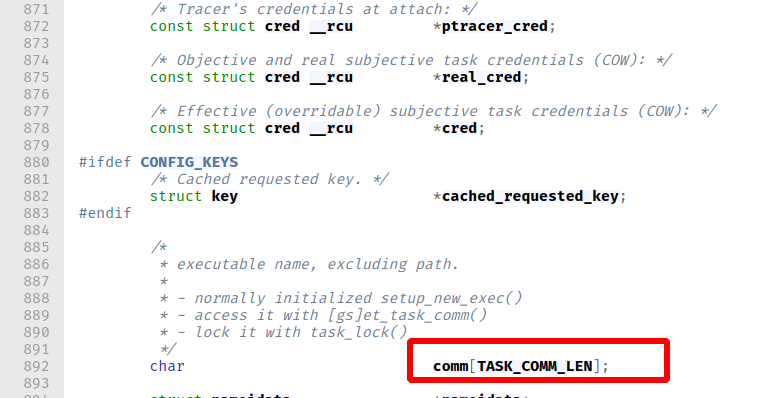
然而,在进程名字并不特殊的情况下,内核中可能会有多个同样的字符串,这会影响搜索的正确性与效率。因此,我们可以使用 prctl 设置进程的 comm 为一个特殊的字符串,然后再开始定位 comm。
修改id
在这种方法下,我们可以直接将 cred 中的 uid-fsgid 都修改为 0。当然修改的方式有很多种,比如说
- 在我们具有任意地址读写后,可以直接修改 cred。
- 在我们可以 ROP 执行代码后,可以利用 ROP gadget 修改 cred。
UAF使用同样堆块
如果我们在进程初始化时能控制 cred 结构体的位置,并且我们可以在初始化后修改该部分的内容,那么我们就可以很容易地达到提权的目的。这里给出一个典型的例子
- 申请一块与 cred 结构体大小一样的堆块
- 释放该堆块
- fork 出新进程,恰好使用刚刚释放的堆块
- 此时,修改 cred 结构体特定内存,从而提权
在这个过程中,我们不需要任何的信息泄露。
修改cred指针
因为要修改cred的指针了,所以我们需要知道cred 指针的具体地址。此时使用上面的间接定位更加方便。
在具体修改时,我们可以使用如下的两种方式
- 修改 cred 指针为内核镜像中已有的 init_cred 的地址。这种方法适合于我们能够直接修改 cred 指针以及知道 init_cred 地址的情况。
- 伪造一个 cred,然后修改 cred 指针指向该地址即可。这种方式比较麻烦,一般并不使用。
commit_creds(prepare_kernel_cred(0))
我们还可以使用 commit_creds(prepare_kernel_cred(0)) 来进行提权,该方式会自动生成一个合法的 cred,并定位当前线程的 task_struct 的位置,然后修改它的 cred 为新的 cred。该方式比较适用于控制程序执行流后使用。
在整个过程中,我们并不知道 cred 指针的具体位置。
改变别人
如果我们可以改变特权进程的执行轨迹,也可以实现提权。这里我们从以下角度来考虑如何改变特权进程的执行轨迹。
- 改数据
- 改代码
改数据
这里给出几种通过改变特权进程使用的数据来进行提权的方法。
符号链接
如果一个 root 权限的进程会执行一个符号链接的程序,并且该符号链接或者符号链接指向的程序可以由攻击者控制,攻击者就可以实现提权。
call_usermodehelper
call_usermodehelper是一种内核线程执行用户态应用的方式,并且启动的进程具有 root 权限。因此,如果我们能够控制具体要执行的应用,那就可以实现提权。在内核中,call_usermodehelper具体要执行的应用往往是由某个变量指定的,因此我们只需要想办法修改掉这个变量即可。不难看出,这是一种典型的数据流攻击方法。一般常用的主要有以下几种方式。
修改modprobe_path
使用传统的kernel漏洞利用手法,调用prepare_kernel_cred()和commit_creds()的过程是一个非常繁琐的过程。所以就有了modprobe_path这个有效简便的方法
修改 modprobe_path 实现提权的基本流程如下
- 获取 modprobe_path 的地址。
- 修改 modprobe_path 为指定的程序。
- 触发执行
call_modprobe,从而实现提权 。这里我们可以利用以下几种方式来触发- 执行一个非法的可执行文件。非法的可执行文件需要满足相应的要求(参考 call_usermodehelper 部分的介绍)。
- 使用未知协议来触发。
这里我们也给出使用 modprobe_path 的模板。
1 | // step 1. modify modprobe_path to the target value |
定位modprobe_path也是有两种方法,直接定位和间接定位。
直接定位
由于 modprobe_path 的取值是确定的,所以我们可以直接扫描内存,寻找对应的字符串。这需要我们具有扫描内存的能力。
间接定位
考虑到 modprobe_path 相对于内核基地址的偏移是固定的,我们可以先获取到内核的基地址,然后根据相对偏移来得到 modprobe_path 的地址。
修改poweroff_cmd
- 修改 poweroff_cmd 为指定的程序。
- 劫持控制流执行
__orderly_poweroff。
定位poweroff_cmd的话可以用类似modprobe_path的定位方法
改代码
在程序运行时,如果我们可以修改 root 权限进程执行的代码,那其实我们也可以实现提权。
修改vDSO代码
内核中 vDSO 的代码会被映射到所有的用户态进程中。如果有一个高特权的进程会周期性地调用 vDSO 中的函数,那我们可以考虑把 vDSO 中相应的函数修改为特定的 shellcode。当高权限的进程执行相应的代码时,我们就可以进行提权。
在早期的时候,Linux 中的 vDSO 是可写的,考虑到这样的风险,Kees Cook 提出引入 post-init read-only 的数据,即将那些初始化后不再被写的数据标记为只读,来防御这样的利用。
在引入之前,vDSO 对应的 raw_data 只是标记了对齐属性。
1 | fprintf(outfile, "/* AUTOMATICALLY GENERATED -- DO NOT EDIT */\n\n"); |
引入之后,vDSO 对应的 raw_data 则被标记为了初始化后只读。
1 | fprintf(outfile, "/* AUTOMATICALLY GENERATED -- DO NOT EDIT */\n\n"); |
通过修改 vDSO 进行提权的基本方式如下
- 定位 vDSO
- 修改 vDSO 的特定函数为指定的 shellcode
- 等待触发执行 shellcode
这里我们着重关注下如何定位 vDSO。
ida定位
这里我们介绍一下如何在 vmlinux 中找到 vDSO 的位置。
- 在 ida 里定位 init_vdso 函数的地址
1 | __int64 init_vdso() |
可以看到 vdso_image_64 和 vdso_image_x32。以vdso_image_64 为例,点到该变量的地址
1 | .rodata:FFFFFFFF81A01300 public vdso_image_64 |
点击 raw_data 即可知道 64 位 vDSO 在内核镜像中的地址,可以看到,vDSO 确实是以页对齐的。
1 | .data:FFFFFFFF81E04000 raw_data db 7Fh ; ; DATA XREF: .rodata:vdso_image_64↑o |
从最后的符号来看,我们也可以直接使用
raw_data来寻找 vDSO。
内存里定位
vDSO 其实是一个 ELF 文件,具有 ELF 文件头。同时,vDSO 中特定位置存储着导出函数的字符串。因此我们可以根据这两个特征来扫描内存,定位 vDSO 的位置。
考虑到 vDSO 相对于内核基地址的偏移是固定的,我们可以先获取到内核的基地址,然后根据相对偏移来得到 vDSO 的地址。
实战
这么多基础知识看起来还是有点meng的,上一个题目看一下吧。
就拿ciscn_babydriver 这个题目看一下
题目拿到手可以看到给了这几个东西。
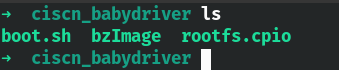
- boot.sh:启动脚本
- bzImage:kernel镜像
- rootfs.cpio:文件系统映像
先看一下第一个boot.sh,可以看到启动参数。

启动一下,因为之前的文章里已经介绍了qemu,这里直接./boot.sh就可以了
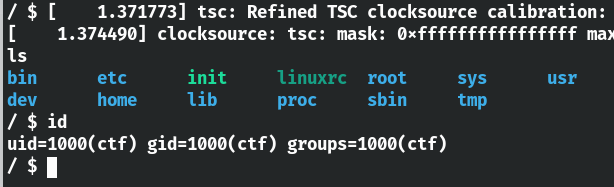
看了一下,ctf的权限找不到flag,应该需要提权到root。将rootfs.cpio文件系统进行解包,拿到里面的驱动逻辑。
1 | $ mkdir File_system |

接下来就是对ko逆向,文件在File_system/lib/modules/4.4.72里
1 | $ file babydriver.ko |
拉进IDA里面看一下babydriver_init这个函数,这个函数是进行参数设置的操作。
1 | __int64 __fastcall babydriver_init() |
相应的babydriver_exit函数也是参数设置的操作,设备卸载时候的会调用的,把分配的设备和class等回收。
1 | void __fastcall babydriver_exit() |
再来看一下open函数和release吧。这两个函数对babydev_struct进行分配内存和释放内存
1 | __int64 __fastcall babyopen(inode *inode, file *filp, __int64 a3) |
babydev_struct.device_buf对它进行分配内存,babydev_struct.device_buf_len = 64LL;buf的长度为64。
接下来就是read函数
1 | size_t __fastcall babyread(file *filp, char *buffer, size_t length, loff_t *offset) |
babydev_struct.device_buf对它时行判空,不为空并且babydev_struct.device_buf_len>v4就可以device_buf拷贝到Buffer里
看一下write函数,read write对应起来
1 | size_t __fastcall babywrite(file *filp, const char *buffer, size_t length, loff_t *offset) |
接着就剩下了最后一个ioctl
1 | __int64 __fastcall babyioctl(file *filp, __int64 command, unsigned __int64 arg) |
先用kfree将babydev_struct.device_buf释放,再kalloc分配一个指定size的内存地址赋给device_buf。
漏洞利用
在分析函数的时候,将babydev_struct.device_buf释放之后,并没有进行清0操作,其实SLAB和SLUB都是内核的内存管理机制和堆管理很类似。这题很明显的存在uaf漏洞。
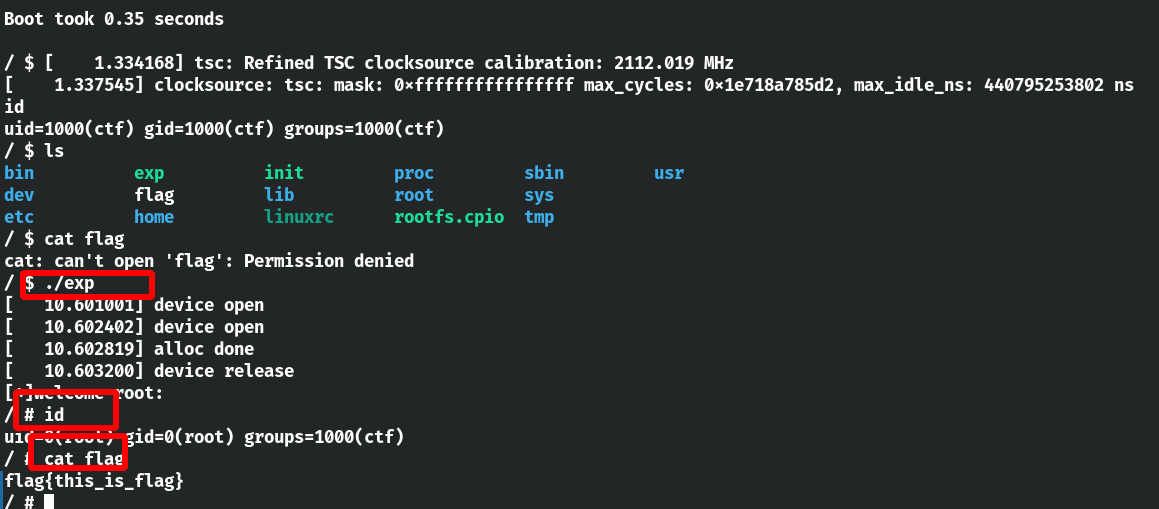
可以修改cred。因为这题有uaf,babydev_struct.device_buf这个是全局变量,所以我们可以申请两次,第二次就可以覆盖第一次,接着可以free掉buf,行成uaf。再fork一个新进程,fork新进程时会分配cred结构体来标明新的权限,调用write向此时的babydev_struct.device_buf中写入28个0,刚好覆盖至uid和gid,实现root提权。其实这题可以看成全局竞争。
下图可以看到kernel的版本4.4.72,cred结构体的总大小是0xa8,一直到gid结束是28个字节。
exp
1 |
|
Reference
https://ctf-wiki.org/pwn/linux/kernel-mode/aim/privilege-escalation/change-others/
https://ctf-wiki.org/pwn/linux/kernel-mode/aim/privilege-escalation/change-self/#_12
https://ama2in9.top/2020/09/03/kernel/